1. 命令行工具¶
若是想快速入门,可略过此小节
命令行工具为boris-spider内置支持的,可方便快速的创建项目、爬虫、item、以及调试请求等,使用方法如下:
1.查看支持的命令行¶
打开命令行窗口,输入spider
> spider
Spider 0.0.4
Usage:
spider <command> [options] [args]
Available commands:
create create spider、parser、item and so on
shell debug response
Use "spider <command> -h" to see more info about a command
可见spider支持create及shell两种命令
2. spider create¶
使用spider create
可快速创建项目、爬虫(parser)、item等,具体支持的命令可输入spider create -h
查看使用帮助
> spider create -h
usage: spider [-h] [-i [...]] [-p] [-s] [-t] [-init] [-j] [-sj]
模版生成器
optional arguments:
-h, --help show this help message and exit
-i [ ...], --item [ ...]
创建item 如 create -i test 则生成test表对应的item。
支持like语法模糊匹配所要生产的表。 若想生成支持字典方式赋值的item,则create -item
test 1
-p , --parser 创建parser 如 spider create -p TestParser
-s , --spider 创建爬虫项目 如 spider create -s test-spider
-t , --table 创建表 如 spider create -t table_name
-init 创建__init__.py 如 spider create -init
-j, --json 创建json
-sj, --sort_json 创建有序json
具体含义解释说明如下:
item:与数据库中的表对应,一个item对应一条数据。生成item需要先在数据库中创建表,然后使用
spider create -i table_name生成,具体用途之后用到时再讲parser:数据解析器,也可以看作为一个爬虫
spider:爬虫项目,当我们编写一个大型项目时首先用到该命令,创建个项目。若是个简单的爬虫,可直接用parser命令,创建个单文件的爬虫即可
table:创建表,可根据json生成表
init:在当前文件夹下创建__init__.py文件,文件内会自动包含当前文件夹下的所有py文件
json:当我们做爬虫时,经常会将浏览器中的请求头拿下来,改成json格式,然后请求时携带。该命令可快速将请求头或请求参数转为json,示例如下:(输入完
spider create -j后敲回车,然后输入需要转换的内容)> spider create -j method: get shareKey: c75d568d62bc101e6ec482ca2fb882f0 unloginId: 5573102e-f32c-acfd-07e0-2e85c13b8c0f { "method": "get", "shareKey": "c75d568d62bc101e6ec482ca2fb882f0", "unloginId": "5573102e-f32c-acfd-07e0-2e85c13b8c0f" }
sort_json 与json命令类似,只不过该命令生成的json是按照key排序的有序字典
3. spider shell¶
下载调试器,可方便测试抽取规则是否正确,输入spider shell -h查看使用帮助
> spider shell -h
下载调试器
usage: spider shell [options] [args]
optional arguments:
-u, --url 抓取指定url
-c, --curl 抓取curl格式的请求
由提示可以看出,支持url及curl两种方式
以url为例,请求百度:
请求
> spider shell -u https://www.baidu.com MainThread|2020-06-21 23:21:37,208|request.py|get_response|line:283|DEBUG| -------------- None.parser request for ---------------- url = https://www.baidu.com method = GET body = {'proxies': None, 'timeout': 22, 'stream': True, 'verify': False, 'headers': {'User-Agent': 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1866.237 Safari/537.36'}} <Response [200]> Python 3.6.3 (v3.6.3:2c5fed86e0, Oct 3 2017, 00:32:08) Type 'copyright', 'credits' or 'license' for more information IPython 7.14.0 -- An enhanced Interactive Python. Type '?' for help. now you can use response In [1]:
测试抽取title的xpath是否正确
In [1]: response.xpath('//title/text()').extract_first() Out[1]: '百度一下,你就知道'
可以看出,我们可以直接使用response, response支持xpath表达式
若想查看都支持哪些函数,可输入
resonse.然后敲两次tab键,如下:
以curl为例,请求百度(通常用来测试post接口比较方便)
打开浏览器检查工具,复制需要测试的接口为curl格式
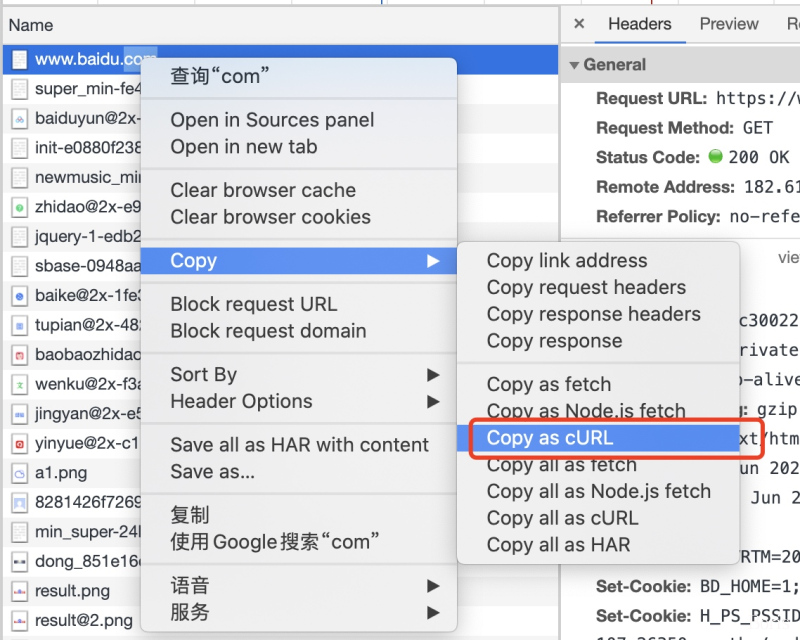
测试 输入
spider shell --, 粘贴刚刚复制的curl> spider shell --curl 'https://www.baidu.com/' \ -H 'Connection: keep-alive' \ -H 'Pragma: no-cache' \ -H 'Cache-Control: no-cache' \ -H 'Upgrade-Insecure-Requests: 1' \ -H 'User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36' \ -H 'Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9' \ -H 'Sec-Fetch-Site: none' \ -H 'Sec-Fetch-Mode: navigate' \ -H 'Sec-Fetch-User: ?1' \ -H 'Sec-Fetch-Dest: document' \ -H 'Accept-Language: zh-CN,zh;q=0.9,en;q=0.8' \ -H 'Cookie: PSTM=1589621705; BAIDUID=BC3B63E7833EB3D77970A2CF9AE7F4A2:FG=1; BIDUPSID=016405978E2364A4AFD0227A36DA60DE; BD_UPN=123253; BDUSS=nl2a3EzNGp-aGdham5xanhVYjZLbXNWTENBRWl0VTJuLTVEUGJOa2VodjhGTzVlRVFBQUFBJCQAAAAAAAAAAAEAAACCgXjpQm9yaXMwNjIxAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAPyHxl78h8ZeW; delPer=0; BD_CK_SAM=1; BD_HOME=1; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; PSINO=1; ZD_ENTRY=google; H_PS_PSSID=1442_31672_21102_32046_31321_30823_32107_26350; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm' \ --compressed MainThread|2020-06-21 23:29:48,773|request.py|get_response|line:283|DEBUG| -------------- None.parser request for ---------------- url = https://www.baidu.com/ method = POST body = {'data': {}, 'headers': {'Connection': 'keep-alive', 'Pragma': 'no-cache', 'Cache-Control': 'no-cache', 'Upgrade-Insecure-Requests': '1', 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9', 'Sec-Fetch-Site': 'none', 'Sec-Fetch-Mode': 'navigate', 'Sec-Fetch-User': '?1', 'Sec-Fetch-Dest': 'document', 'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8', 'Cookie': 'PSTM=1589621705; BAIDUID=BC3B63E7833EB3D77970A2CF9AE7F4A2:FG=1; BIDUPSID=016405978E2364A4AFD0227A36DA60DE; BD_UPN=123253; BDUSS=nl2a3EzNGp-aGdham5xanhVYjZLbXNWTENBRWl0VTJuLTVEUGJOa2VodjhGTzVlRVFBQUFBJCQAAAAAAAAAAAEAAACCgXjpQm9yaXMwNjIxAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAPyHxl78h8ZeW; delPer=0; BD_CK_SAM=1; BD_HOME=1; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; PSINO=1; ZD_ENTRY=google; H_PS_PSSID=1442_31672_21102_32046_31321_30823_32107_26350; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm'}, 'proxies': None, 'timeout': 22, 'stream': True, 'verify': False} <Response [200]> Python 3.6.3 (v3.6.3:2c5fed86e0, Oct 3 2017, 00:32:08) Type 'copyright', 'credits' or 'license' for more information IPython 7.14.0 -- An enhanced Interactive Python. Type '?' for help. now you can use response In [1]: